
The process of grinning looks too healing~

Let's just say that the waste film of bear child / hairy child in the camera is finally saved!
And I can't see the effect of post synthesis at all, as if it was originally shot.
This is the result of the recent joint launch of Google, Cornell University and the University of Washington. It can restore 3D moments with only 2 similar photos. At present, it has been included in CVPR 2022.
The author of the first and second works are Chinese, and the first little sister graduated from Zhejiang University.
Use 2 photos to predict the middle scene
This method applies to two very similar photos, such as a series of photos produced during continuous shooting.
The key of the method is to convert two images into a pair of feature-based layered depth images (LDI), and enhance them through scene flow.
The whole process can regard the two photos as "starting point" and "ending point" respectively, and then gradually predict the changes at each moment between the two.
Specifically, the process is as follows:
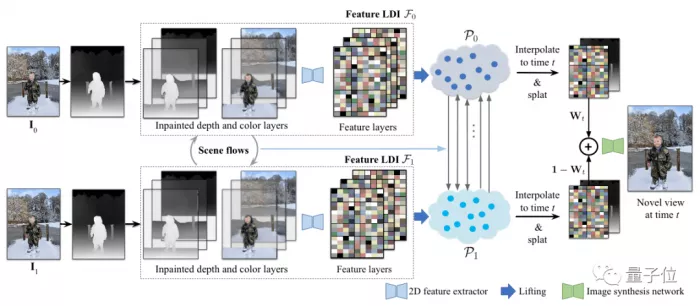
Firstly, align the two photos with homography matrix to predict the dense depth map of the two photos respectively.
Then each rgbd image is converted into color LDI, and the occluded part of the background is repaired by depth perception.
Among them, RGB image is ordinary RGB image + depth image.

Then, the two-dimensional feature extractor is used to repair each color layer of LDI to obtain the feature layer, so as to generate two feature layers.
The next step is motion simulation.
By predicting the depth and optical flow between two input images, the scene flow of each pixel in LDI can be calculated.
If you want to render a new view between the two images and promote it to 3D, you need to promote the two groups of LDI with eigenvalues to a pair of 3D point clouds, and move to the middle point in time along the scene flow in both directions.
Then, the three-dimensional feature points are projected and expanded to form forward and reverse two-dimensional feature maps and corresponding depth maps.
Finally, the final effect can be obtained by linearly mixing these mappings with the weights of the corresponding time points in the timeline and transmitting the results to the image synthesis network.
experimental result
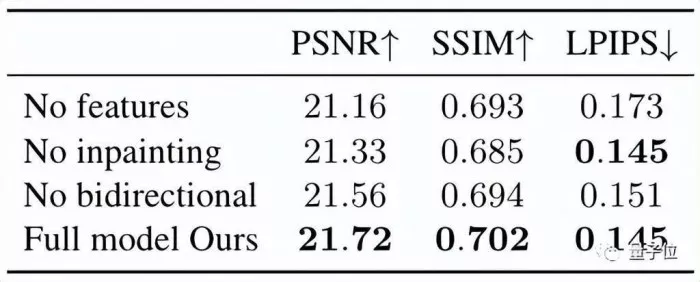
In terms of data, this method is higher than the baseline level in all error indicators.
On the UCSD dataset, this method can retain more details in the picture, as shown in (d).

Ablation experiments on NVIDIA dataset show that this method is also good in improving rendering quality.
However, there are some problems: when the change between the two images is relatively large, the phenomenon of object dislocation will appear.
For example, in the figure below, the mouth of the wine bottle moved, and the wine glass that should not have changed shook.

In addition, if the photos are not taken completely, there will inevitably be "amputation" during synthesis, such as the hand feeding koala in the figure below.

Team Introduction

A of the study is Qianqian Wang , who is now a doctoral student at Cornell University.
She graduated from Zhejiang University and studied with Zhou Xiaowei.
Research interests include computer vision, computer graphics and machine learning.

The second work is Zhengqi Li , who graduated from Cornell University with a doctor's degree and a bachelor's degree from the University of Minnesota. He is currently working at Google research.
He was nominated for CVPR 2019 best thesis, Google 2020 doctoral award and adobe research scholarship in 2020, and was shortlisted in Baidu's top 100 AI Chinese stars in 2021.

Also participating in the study was Professor Brian curless of the University of Washington.
He also proposed another method to achieve a similar effect, which also uses only two photos to generate coherent video through a new frame interpolation model.

Thesis address: